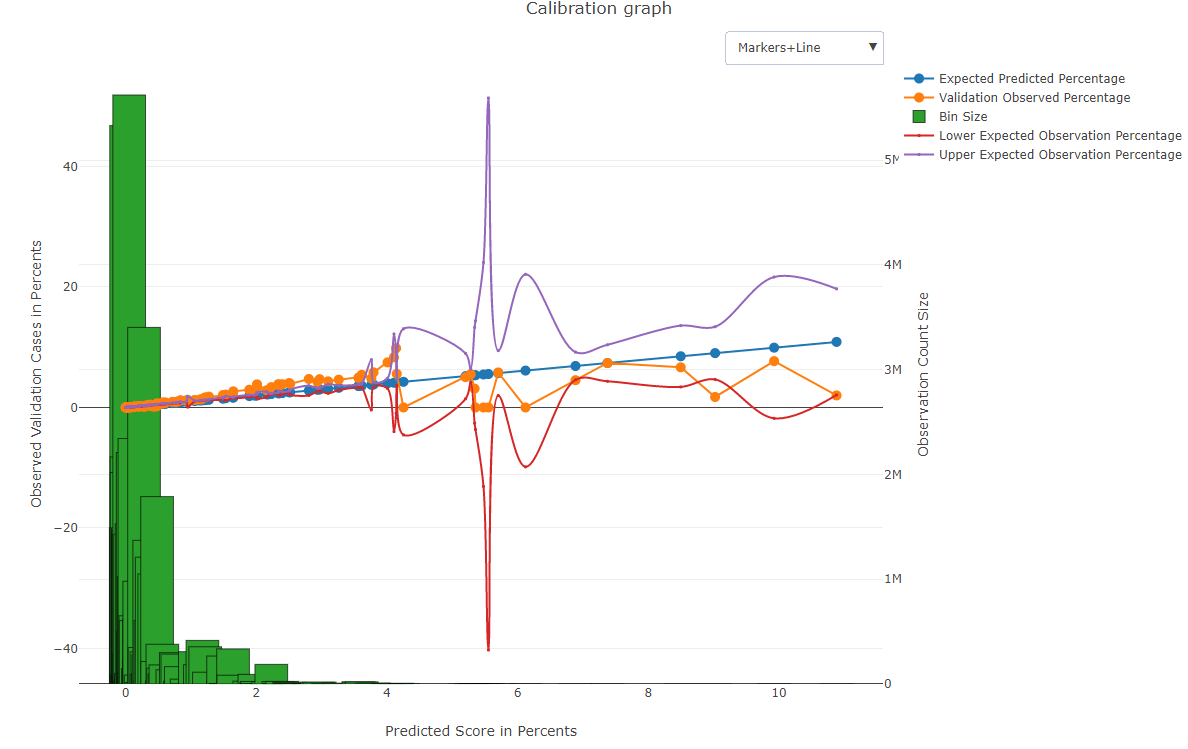
Calibrate model, and calibration test
****: Calibrate a model on one repository, and check calibration on another repository.
--filter_train 0 --rep $REP --filter_by_cohort "Time-Window:0,365" --samples $SAMPLES --output $OUTPUT --json_mat $JSON
Time Window should be 0 to horizon. Thus, 0,365 means calibrated risk for outcome within 1 year. And 0,730 would mean calibrated risk for outcome within 2 years.
json_mat is required even though it has no effect (to be removed)
filter_train default is 1 => take just train. As we set '0' - all samples are taken.
Standard predict for the samples generated previously.
--get_model_preds --rep $REP --f_samples $INPUT --f_model $MODEL --f_preds $PREDS_FOR_CALIBRATION
--postProcessors $JSON --rep $REP --samples $PREDS_FOR_CALIBRATION --inModel $MODEL --skip_model_apply 1 --out $OUTPUT
The OUTPUT is a model with calibration
The terminal output is 'staircase graph' - bins and calibrated risk (printed on screen and reachable through Flow --print_model_info)
Output format example:
{
"post_processors" : [
{
"action_type" : "post_processor" ,
"pp_type" : "calibrator" ,
"calibration_type" : "isotonic_regression" ,
"use_p" : "0.25"
}
]
}
Run the program:
--rep ${ REP } --tests_file ${ TEST } --output ${ OUT_PATH }
File with expected risk and actual in validation, for each bin of the calibrated model, e.g., plus some KPIs: