Test 06 - Compare Score Distribution
Purpose
Compare model score distributions between the reference dataset (training matrix) and the new test repository. This validates that score moments, cutoffs, and distributional shape are consistent and helps detect shifts that could affect model performance.
Required Inputs
From configs/env.sh:
WORK_DIR: Working directory where repository, samples, predictions, and compare artifacts are storedREFERENCE_MATRIX: Full path to the reference feature matrix (used to recreate reference predictions)MODEL_PATH: Path to the fitted Medial model (the test will default to${WORK_DIR}/model/model.medmdl) and depends on Test 02- Optional environment controls used by the TestKit:
MEMORY_LIMIT(limits model memory usage), and the samples created by Test 03 under${WORK_DIR}/Samples(especially3.test_cohort.samplesand1.all_potential.samples)
How to Run
From your TestKit folder, execute:
Check ${WORK_DIR}/compare for produced score reports and HTML visualizations.
What This Test Does
High-level flow:
- Ensures
MODEL_PATHis set (uses${WORK_DIR}/model/model.medmdlby default) - Generates model predictions for the full potential sample set (
${WORK_DIR}/predictions/all.preds) and for the test cohort (${WORK_DIR}/compare/3.test_cohort.preds) using Flow get_model_preds - Converts
REFERENCE_MATRIXrows into a predictions-like TSV (${WORK_DIR}/compare/reference.preds) when needed - Computes basic score moments (mean, STD) for Reference, Test_Run, and Test_Run.Original (if available) and writes them to
${WORK_DIR}/compare/compare_score.txt - Produces a binned score distribution TSV
${WORK_DIR}/compare/score_dist.tsvand an HTML histogram${WORK_DIR}/compare/score_dist.html - Runs
compare_scores.py(helper script) to compute additional statistics and saves its outputs under${WORK_DIR}/compare - Runs bootstrap analyses (bootstrap_app) to compute score-related performance measures and formats them with
bootstrap_format.pyintocompare_score.txt
The script includes timestamp checks and will avoid re-running expensive prediction steps when outputs are up to date.
Output Location
${WORK_DIR}/compare/compare_score.txt- textual summary with means, stds and formatted bootstrap measures${WORK_DIR}/compare/score_dist.tsv- binned score distribution (Reference vs Test_Run)${WORK_DIR}/compare/score_dist.html- histogram visualization (Plotly)${WORK_DIR}/compare/3.test_cohort.predsand${WORK_DIR}/predictions/all.preds— prediction files used for analysis- Bootstrap reports:
${WORK_DIR}/compare/bt.*.pivot_txtand related formatted outputs
How to Interpret Results
- Compare the mean and STD lines in
${WORK_DIR}/compare/compare_score.txtforReference,Test_Run, andTest_Run.Original.Test_RunandTest_Run.Originalshould be nearly identical (exactly identical is expected in most cases). This compares AlgoAnalyzer scores and our execution of scores. Minor difference might exists due to floating point percision implemnetation of AlgoAnalyzer. There might be difference fromReference. - If
Test_RunandTest_Run.Originaldiffer, the test prints Pearson and Spearman correlations and RMSE (helpful to detect computation mismatches). Small numeric differences may occur in some historical configurations (e.g., LGI). - Inspect
score_dist.htmlto visually compare the two score histogramsReferenceandTest_Run. Large shifts or multimodal changes may indicate distributional drift or population differences. - Review bootstrap measures (
SCORE@PR) to see changes in relevant score cutoffs (for example, top-percentile performance).
Common failure modes and suggestions
- Missing samples/predictions: Ensure Test 03 ran successfully and
${WORK_DIR}/Samples/3.test_cohort.samplesexists. If not, re-run sample generation. Flownot found or model load issues: Verify the Medial runtime andFlowbinary are available in PATH and thatMODEL_PATHpoints to a valid model file.- Memory errors during prediction: Set
MEMORY_LIMITinconfigs/env.shor increase available memory on the host. The script will inject a model-change flag to limit in-memory data ifMEMORY_LIMITis set.
Example output snippets
Contents of ${WORK_DIR}/compare/compare_score.txt (example):
- Score distribution compare:
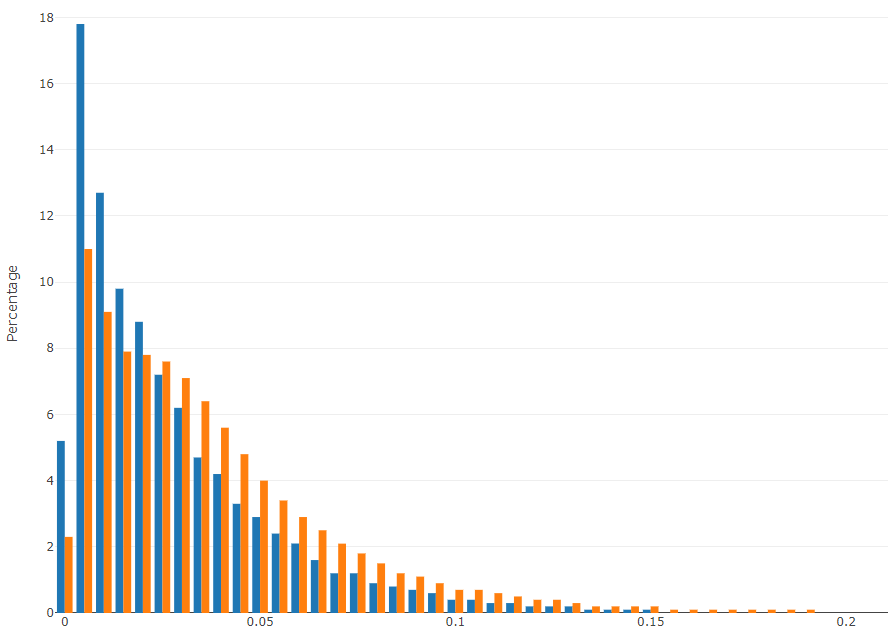
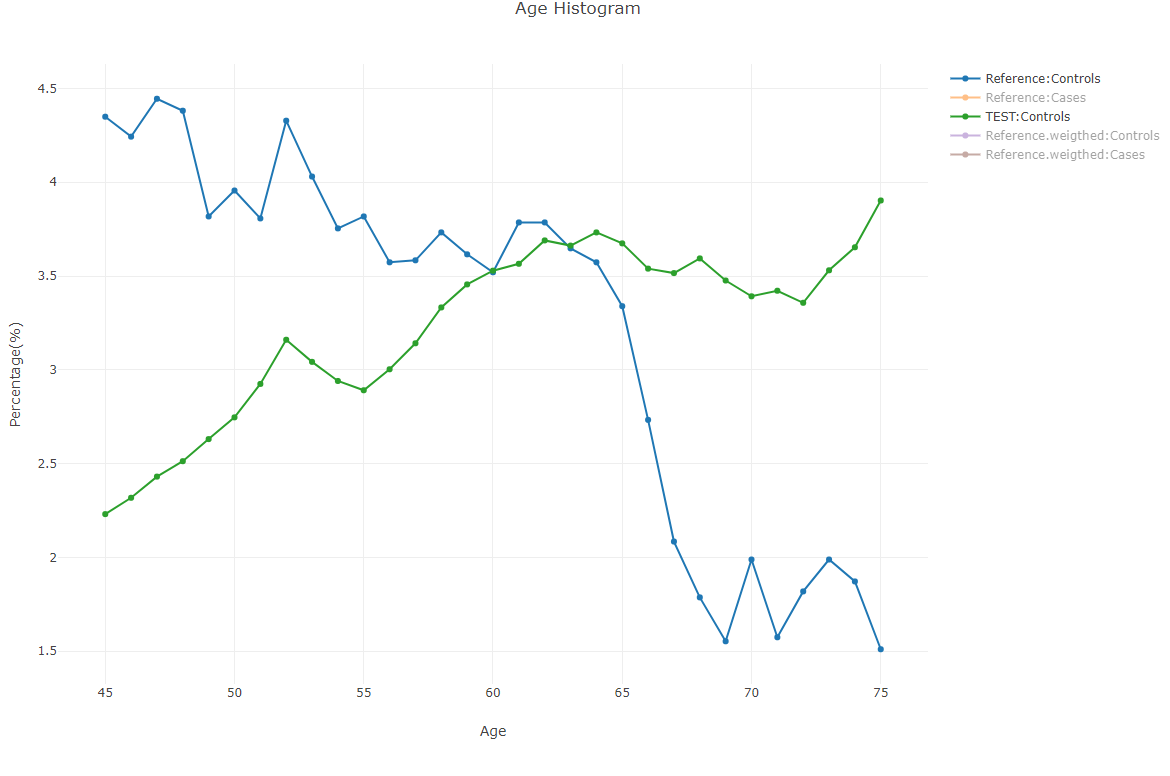
- Age distribution compare:
Notes and Implementation Details
- The script patches a Plotly HTML template so the generated
score_dist.htmlreferencesjs/plotly.jsrelative to the docs/site structure. - Reference predictions are synthesized from
REFERENCE_MATRIXby extracting columns assumed to contain the predicted score (awk transformation used in script). compare_scores.py(inresources/lib) performs more detailed numeric comparisons and writes additional logs under${WORK_DIR}/compare.
Troubleshooting
- If HTML plot is blank or doesn't render, confirm
${WORK_DIR}/tmp/plotly_graph.htmlexists and thatjs/plotly.jsis available at the path expected by the patched HTML template.
Test Results Review
Primary files to inspect after running this test:
${WORK_DIR}/compare/compare_score.txt${WORK_DIR}/compare/score_dist.htmland${WORK_DIR}/compare/score_dist.tsv${WORK_DIR}/predictions/all.predsand${WORK_DIR}/compare/3.test_cohort.preds- Bootstrap reports:
${WORK_DIR}/compare/bt.*.pivot_txt